Orchestrating Reliability:
Scalable and Durable Task Execution
Build long-running workflows with durable checkpoints, stateful milestones, and automated retry patterns. Ensure reliability with built-in state management and fault tolerance, seamlessly handling failures and maintaining execution consistency across distributed processes.
Build Robust Applications: Reliable and Scalable Orchestration
Create resilient applications with built-in durability, fault tolerance, and scalable execution patterns. Orchestrate tasks with ease, handle long-running processes, and seamlessly manage state across distributed workflows—ensuring reliability even in dynamic environments.
Durable Sleep: Suspend without Consuming Resources
Delay task execution reliably with durable sleep, allowing commands to suspend for seconds, minutes, or even days without consuming resources. When the sleep duration ends, execution resumes seamlessly from where it left off.
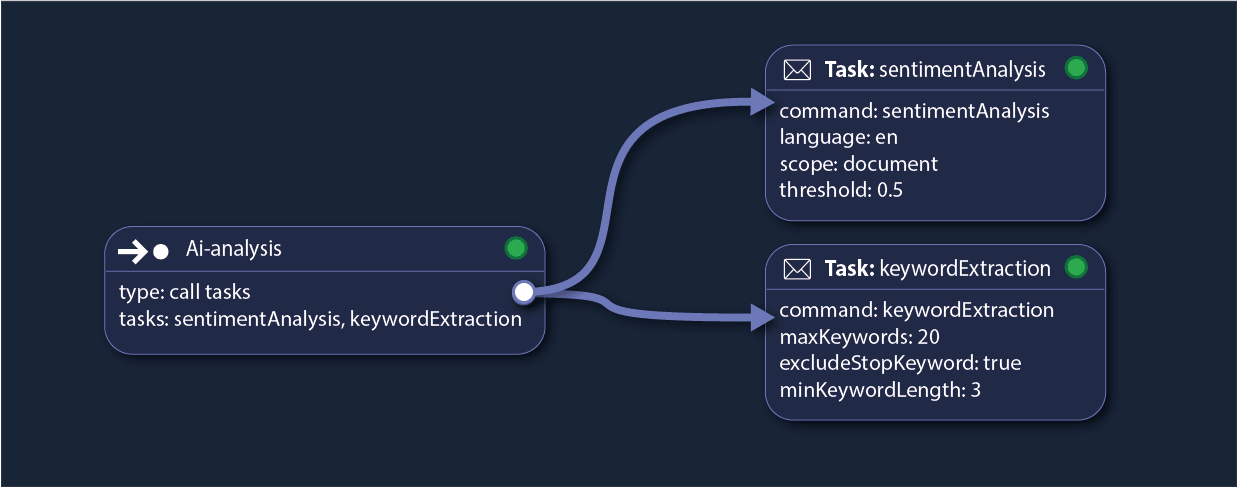
Orchestrate with Subtasks Scalable and Composable Workflows
Break down complex workflows into manageable subtasks, enabling modular and scalable orchestration. Subtasks can be independent executions or sub-orchestrations, ensuring seamless coordination while maintaining full state tracking and durability.
With built-in fault tolerance and retry mechanisms, each subtask runs reliably, allowing workflows to scale dynamically while preserving execution consistency.
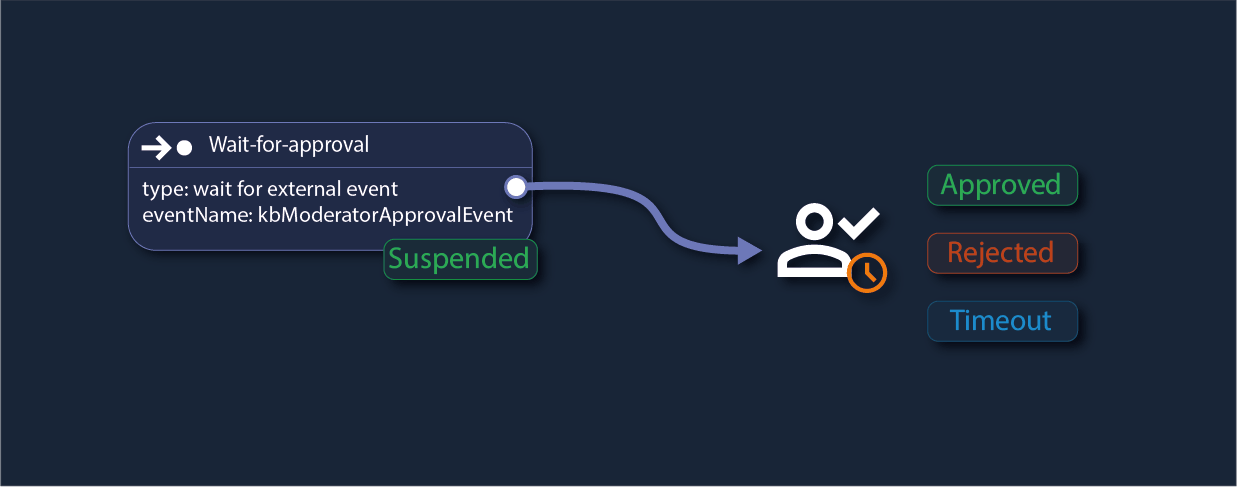
Waiting for External Events: Suspend until Human Approval or Application Events
Suspend commands and workflows until external events are received, like signals from applications or human input.
Easily implement approval-based workflows by pausing execution until a decision is received. When a task reaches an approval step, it waits for an explicit "Raise Event" call, ensuring that the process remains idle without consuming resources.
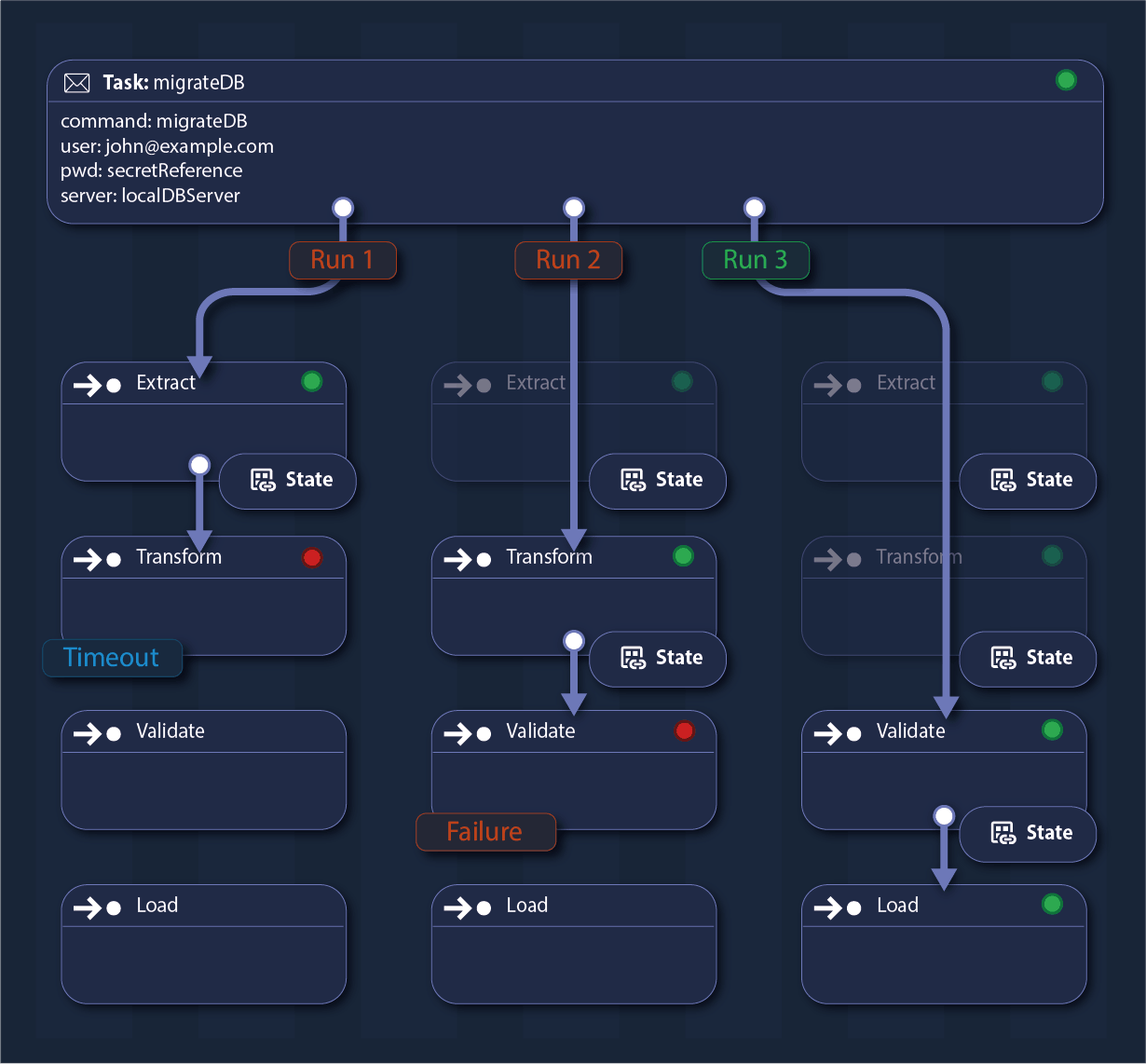
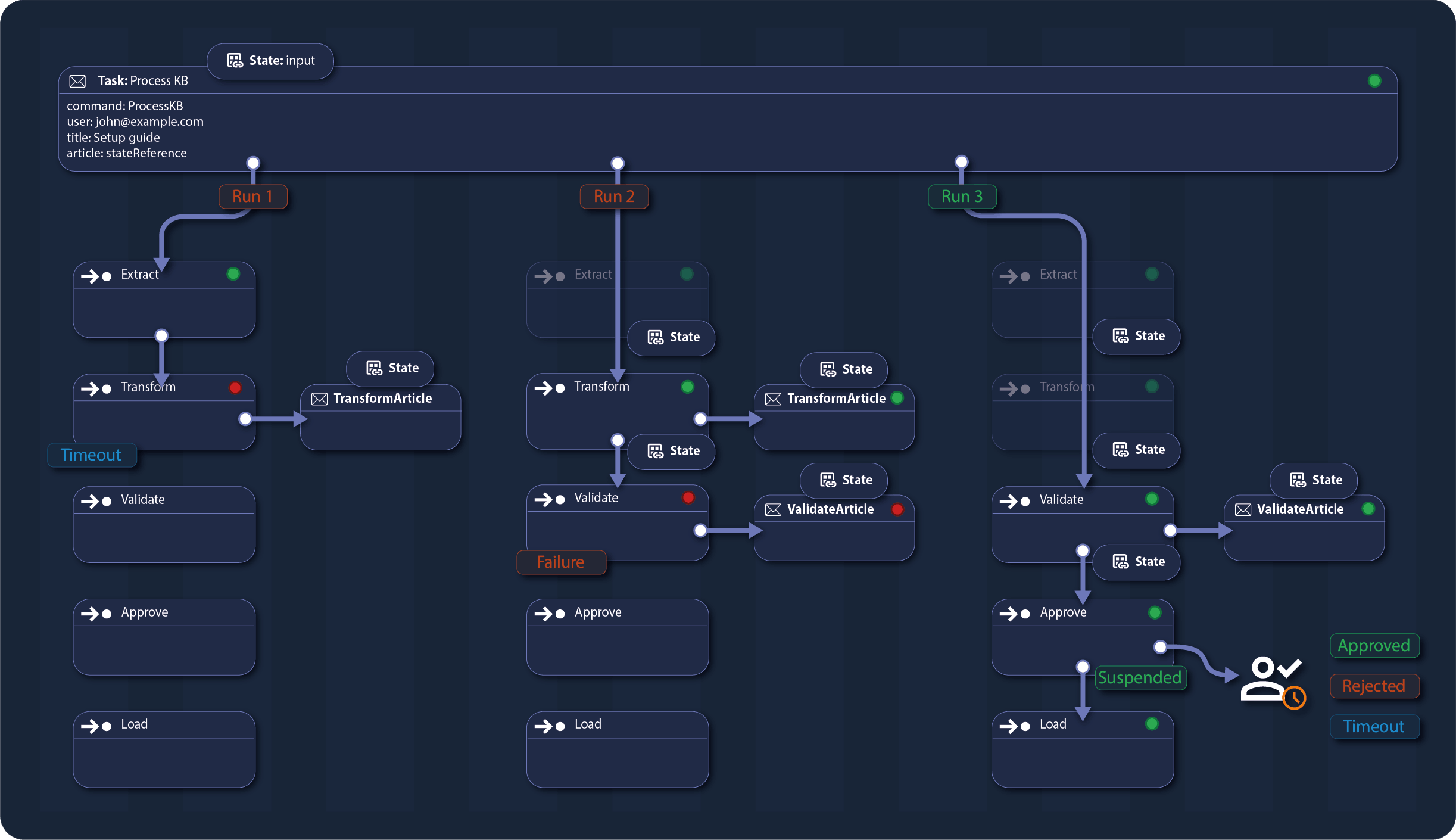
Durable Checkpoints: Build Long-Running Fault-Tolerant Operations
Run long-running processes with built-in reliability and stateful milestones, ensuring progress is never lost.
Prevent failures from disrupting critical operations with automatic and configurable retry policies.
Each checkpoint persists its state, allowing seamless recovery from failures or retries without redoing completed work.
This approach optimizes resource efficiency while providing fault tolerance, enabling operations to resume precisely from the last saved state.